And copy, store, and present the data!
Table of Contents
Intro and Overview
What is this thing?
At We Adopt Greyhounds (WAG), a non-profit greyhound adoption group, an awesome feature has been implemented that allows website users to browse WAG Facebook and Instagram feeds without requiring a Facebook or Instagram account. This was made possible through a fun solution involving n8n, Vue InstantSearch, Meilisearch, and an S3 bucket.
The primary purpose of this feature is to showcase WAG’s social media content directly on their website, enhancing the user experience and providing up-to-date information about their activities.
API and Token Requirements for the Facebook Graph API
Before diving into the technical details, it’s essential to understand the API requirements for the Facebook Graph API and the limitations imposed on API tokens. WAG’s approach, while compliant with privacy and legality regulations, required thoughtful navigation of token types and lifespans.
Scope of access
Here’s some specific examples of what you can and cannot do with a Page token:
Can
Accessing Page-related Data: With a Page token, you can retrieve data related to a specific Facebook Page. This includes fetching posts, comments, likes, and other interactions associated with the Page.
Posting Content as the Page: A Page token enables you to publish content, such as status updates or media, on behalf of the Page itself. This functionality is often leveraged by social media management tools to schedule posts.
Moderating Page Content: Using a Page token, you can moderate comments on the Page’s posts, providing control over the conversations and user interactions.
Fetching Insights: Page tokens allow access to valuable Page insights, providing valuable analytics and performance metrics to help gauge the Page’s reach and engagement.
Cannot or Limited
User-specific Data: Page tokens are limited in their ability to access user-specific data. For instance, you cannot retrieve personal details, such as private messages or non-public information, about users interacting with the Page.
Restricted Endpoints: Some API endpoints are exclusive to User tokens. As a result, using a Page token may not grant access to certain user-related data or interactions.
User Authentication: Unlike User tokens, Page tokens do not allow direct user authentication. Therefore, you cannot use a Page token to log in users to an application or website.
Lifespan: Similar to User tokens, Page tokens also have a limited lifespan. They may expire after a certain period, requiring you to refresh or regenerate them periodically.
More information about Facebook’s Graph API will be in the following sections, and can be found here.
Create a Facebook “App”
Yes this is required
The Importance of a Facebook App
Before delving into the setup process, let’s understand the significance of creating a Facebook app. A Facebook app acts as the bridge between your application and the Facebook Graph API. It provides a unique App ID and App Secret, which are essential for authenticating and accessing Facebook data programmatically.
To create the Facebook app-
Log in to Facebook for Developers: If you don’t have a Facebook account, create one. Then, go to the Facebook for Developers website and log in with your Facebook credentials.
Create a New App: Once logged in, navigate to the Developer Dashboard and click on the “Create App” button. Choose “For Everything Else” as the app category.
Set Up Basic Info: Provide a display name for your app, a contact email, and select the purpose of your app. Click on “Create App ID” to proceed.
Configure App Settings: In the left-hand sidebar, go to “Settings” and then “Basic.” Here, you can configure various settings like the app domain, privacy policy URL, etc.
Add Platform: To use the Facebook Graph API, you need to add a platform. Click on the “Add Platform” button and select “Website.”
Configure Website Platform: Enter your website URL and click on “Save Changes.”
Obtain App ID and App Secret: In the “Settings” > “Basic” section, you’ll find your App ID and App Secret. These will be used in almost every api interaction.
Using the Facebook App Without Verification
While Facebook verification offers added benefits and access to more API features, some use cases may not require full verification. WAG managed to utilize their Facebook app without going through the entire verification process, thanks to certain exemptions provided by Facebook.
Limitations of Unverified Apps:
Email and Ownership Limitations: Unverified apps can only access data from users who have a role in the app development or are listed in the app’s roles. Additionally, they can only send messages to users who have a role in the app or are administrators, developers, or testers of the app.
In the case of WAG, I’m the only developer so it greatly simplifies the concerns of ownership and access.
Endpoint Restrictions: Unverified apps have restricted access to certain API endpoints. For example, they cannot access data from the Facebook Marketing API.
For more details on the verification process and the capabilities of unverified apps, refer to the Facebook App Verification documentation.
Facebook API tokens
Facebook Graph API uses two main types of tokens: User tokens and Page tokens.
User Tokens:
User tokens are obtained after a user grants permission to an application. These tokens are specific to the user who granted access and can be used to access user-related data, such as their posts, photos, and friends.
Page Tokens:
Page tokens, on the other hand, are acquired by granting permission to a Facebook Page associated with the app. These tokens provide access to the Page’s data, including posts, comments, and insights.
Endpoints Accessible from User Tokens but not Page Tokens, and Vice Versa
User tokens allow access to user-specific data, such as retrieving a user’s profile information or their posts. However, some endpoints, like accessing a user’s friend list or private messages, are exclusive to User tokens and not accessible with Page tokens.
On the flip side, Page tokens enable access to data related to the Facebook Page they are associated with. This includes posts, comments, and insights for the Page. However, certain endpoints, such as accessing a user’s private information or friend list, are not available with Page tokens.
In WAGs case, the only data we need is the data from the WAG Facebook page, so we can use a Page token.
Short Lived Tokens and Long Lived Tokens
Tokens obtained through the typical authentication process have a short lifespan, usually lasting a few hours. These are known as short-lived tokens. To extend the token’s lifespan, you can exchange it for a long-lived token, which usually lasts about 60 days. This can be done by making a specific API call to exchange the token.
The Graph API explorer (More on this in a bit) makes grabbing most tokens easy.
The Elusive Permanent Token
While long-lived tokens last significantly longer, Facebook does not offer a direct method to obtain a token with an indefinite lifespan. However, there is a workaround to make a long-lived token “almost” permanent.
Short-lived Token to Long-lived Token
First, exchange a short-lived token for a long-lived token using the /oauth/access_token endpoint. Here’s an example API call using cURL:
1
2
3
4
curl -i -X GET "https://graph.facebook.com/oauth/access_token?grant_type=fb_exchange_token&
client_id=APP-ID&
client_secret=APP-SECRET&
fb_exchange_token=SHORT-LIVED-USER-ACCESS-TOKEN"
Making the Long-lived Token “Permanent”
To extend the long-lived token’s lifespan beyond 60 days, you need to make one more api call.
1
2
3
curl -i -X GET "https://graph.facebook.com/PAGE-ID?
fields=access_token&
access_token=LONG-TOKEN"
This step must be done before the token expires.
While this method makes the token “permanent” in the sense that it no longer has an expiration date, it is crucial to note that Facebook can still invalidate or revoke the token under certain circumstances, so it’s not truly permanent.
Tip: Use the Facebook Access Token Debugger to test your tokens and learn more about them.
Endpoint Restrictions for Permanent Tokens
Despite the extended lifespan, permanent tokens have their limitations. Certain sensitive endpoints, such as accessing user messages or friend lists, are still not accessible with permanent tokens due to privacy and security considerations.
Instagram Tokens: Almost Identical to Facebook
It’s worth noting that Instagram API tokens follow a similar structure and lifespan as Facebook tokens. Instagram’s User tokens grant access to user-specific data, while Page tokens provide access to data related to an Instagram Business or Creator account. Like Facebook tokens, Instagram tokens can also be exchanged for long-lived tokens and have endpoint restrictions.
For detailed information about Facebook API tokens and the API calls involved, you can refer to the official Facebook Graph API Documentation and Instagram Basic Display API Documentation.
Some Example Queries for Common Endpoints
Fetching User Profile Information:
1
/me?fields=id,name,email
This query retrieves the logged-in user’s ID, name, and email.
Getting Page Posts:
1
/PAGE_ID/posts
Replace PAGE_ID with the ID of the Facebook Page you want to retrieve posts from. This query returns a list of posts on the specified Page.
Fetching Page Insights:
1
/PAGE_ID/insights?metric=page_fan_adds,page_impressions
This query retrieves insights for the specified Page, including metrics such as new page likes and page impressions.
Getting User’s Friends:
1
/me/friends
This query returns a list of the logged-in user’s friends.
Posting on a Page:
1
/PAGE_ID/feed
Use a POST request to this endpoint with the necessary parameters to create a new post on the specified Page.
Use the Graph API Reference, and the Graph API Explorer to test queries and learn more about the available endpoints.
A note about the reference documentation The endpoints are nested, so if you want to work with a Page click Page in the left bar, then click Feed inside that new list, to see the endpoints for the Page Feed.
n8n Setup
Brief Hosting Overview
Setting up n8n is relatively straightforward, and you have a couple of hosting options to choose from. You can either install n8n locally if you have Node.js installed, or you can use their Docker container for easy deployment.
Local Installation:
To install n8n locally, you need to have Node.js and npm (Node Package Manager) installed on your system. You can follow the installation instructions for your specific operating system from the official n8n documentation.
Using Docker:
Docker provides a convenient way to deploy n8n as a containerized application. You can use the official n8n Docker image, n8nio/n8n, to quickly set up and run n8n without worrying about dependencies. Refer to the n8n Docker installation guide for step-by-step instructions.
No Special Nodes Needed
n8n comes with a wide range of built-in nodes that cover various functionalities and services, including the Facebook Graph API (Up to v15 anyway, which still works fine). If you want to use Meilisearch without custom HTTP nodes, I have made a community node for that n8n-nodes-meilisearch, which isn’t perfect- but it’s easier than crafting the calls myself. Detailed, official instructions here for how to install and manage community nodes
CDN Setup
Using Digital Ocean Spaces as an S3-Compatible CDN
For the CDN setup, WAG opted to use Digital Ocean Spaces, a scalable and cost-effective object storage service compatible with the S3 API. Digital Ocean Spaces provides an easy way to store and serve large amounts of media, such as images and videos, with low latency and high availability.
Also the GUI looks like a human could actually use it: 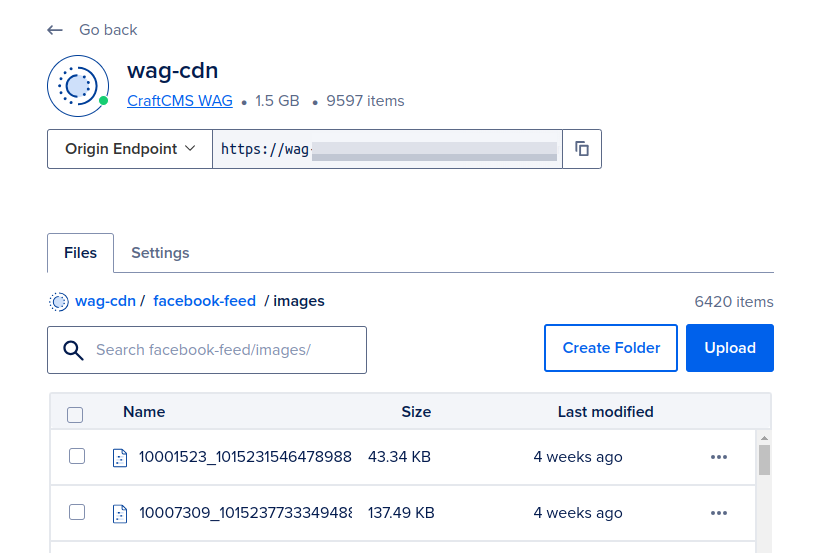
API Access to the Bucket(s)
To access the bucket(s) hosted on Digital Ocean Spaces from your application or backend, you’ll need to configure API access. In your Digital Ocean account, navigate to “API” in the left-hand sidebar and click on “Generate New Token.” Give the token a name, select the desired scopes, and click “Generate Token.” Save the access key and secret key provided.
Other providers like AWS will have their own ways of getting tokens and assigning permissions. This is mainly why I use Digital Ocean Spaces, it’s just easier.
n8n workflow
Excuse me, I was told there would be web scraping
Scraping FB and IG into Meilisearch 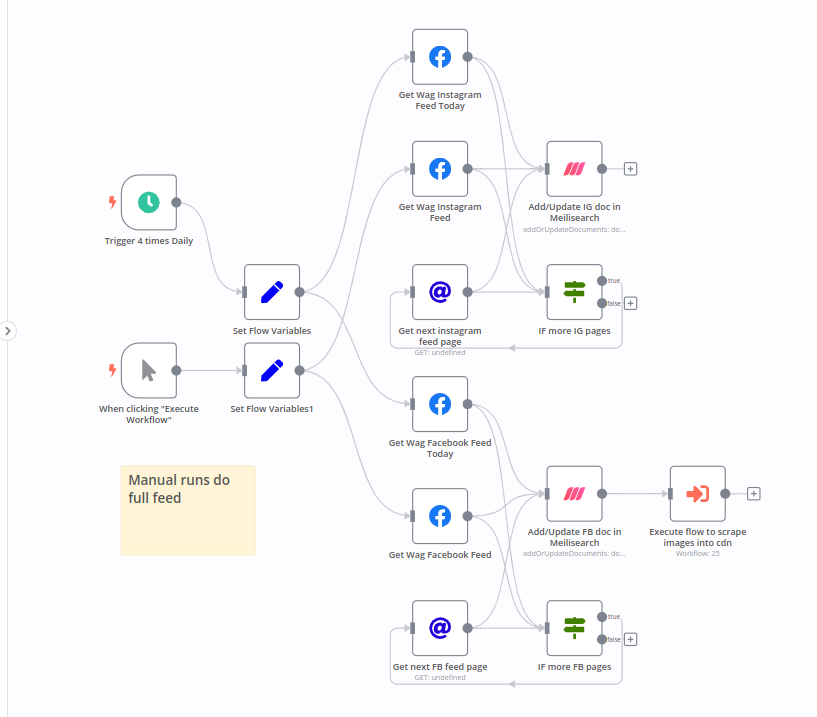
Downloading images and storing them in the CDN 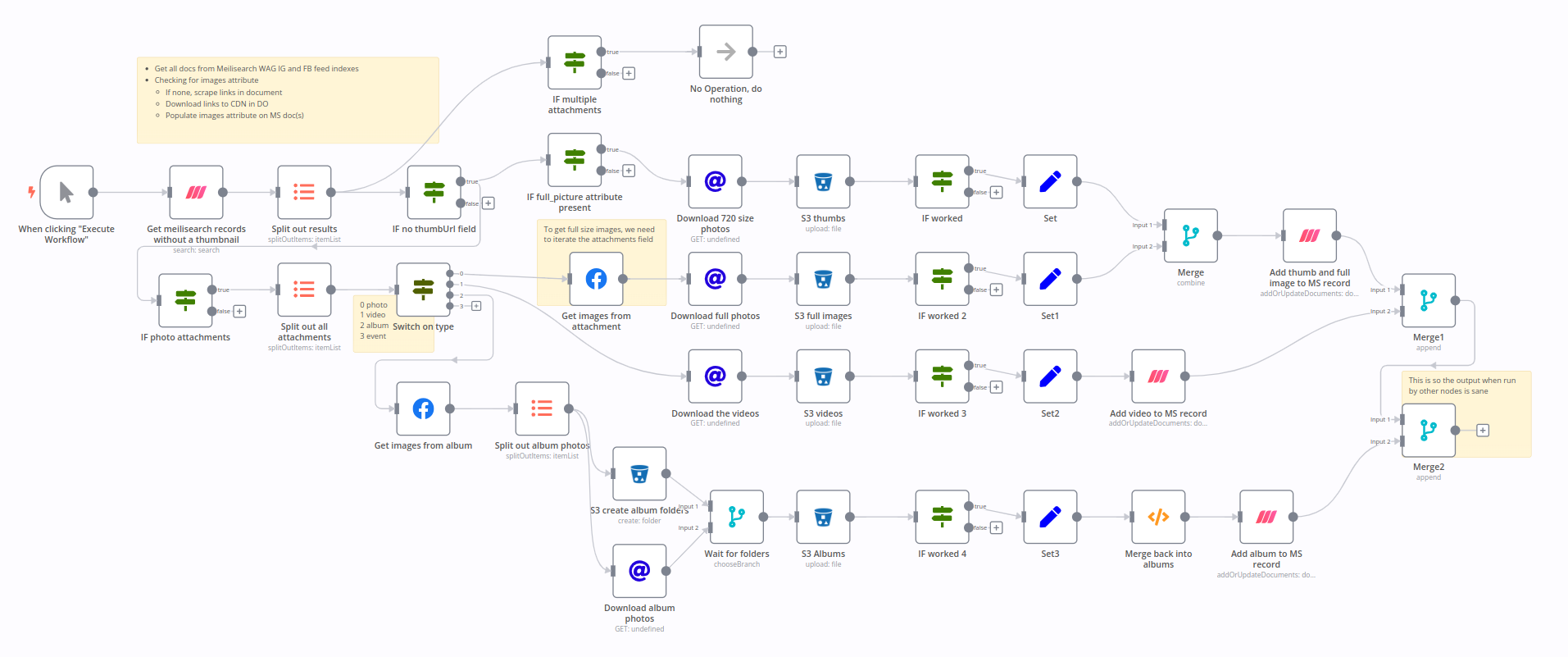
Logic and Flow
The n8n workflow is relatively straightforward.
- It starts with a trigger node that runs every 4 hours, or manually.
- The trigger node is followed by a Facebook node that fetches the latest posts from the WAG Facebook page.
- The data is then passed pretty much as is to Meilisearch,
- and then checked for a “Next Page” link before..
- ..using an HTTP node to follow the ‘next page’ link
- Repeat until no more
Here’s what the initial Facebook node looks like for the page feed: 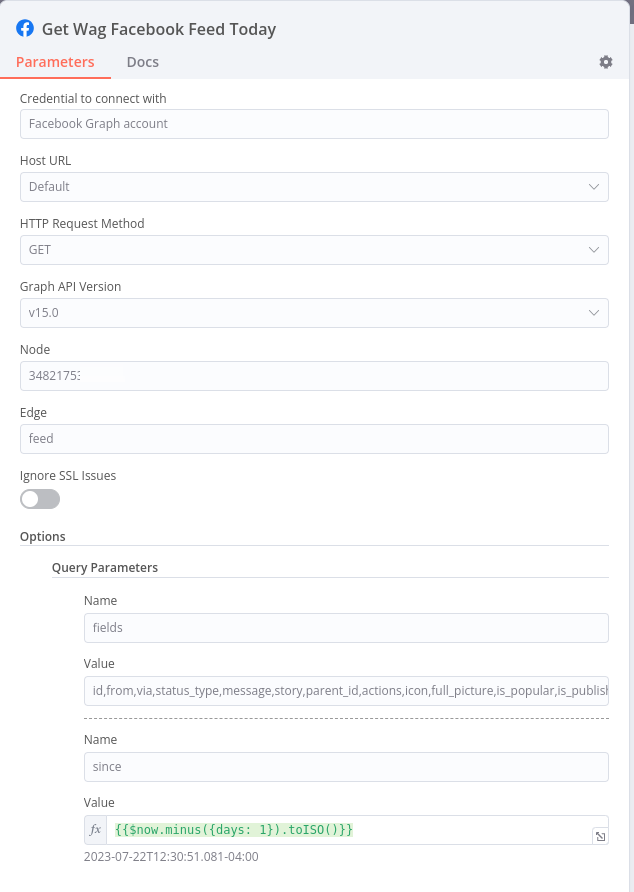
Looks easy, but without the Graph API Explorer, the following query would have driven me mad. I’m breaking it onto multiple lines so it’s easier to see what’s going on. Paste this in the explorer for your own page, and you’ll see what I mean.
1
2
3
4
5
6
id,from,via,status_type,message,story,parent_id,actions,icon,full_picture,is_popular,is_published,properties,shares,
# Similar to graphql, we can nest fields and arguments in some cases
attachments.limit(10){title,url,description,type,media_type,media,description_tags,target,unshimmed_url},
reactions{id,name,type,pic,picture},
likes{id,name,link},
story_tags,message_tags,created_time,updated_time,permalink_url
This produces a document like this: (Expand the thingy)
Click to expand
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
{
"id": "348217539882_671041618397093",
"from": {
"name": "We Adopt Greyhounds, Inc (WAG)",
"id": "redacted"
},
"status_type": "added_photos",
"message": "lotto text - mimics the description field",
"actions": [
{
"name": "Like",
"link": "https://www.facebook.com/633917458776176/posts/671041618397093"
},
{
"name": "Comment",
"link": "https://www.facebook.com/633917458776176/posts/671041618397093"
},
{
"name": "Share",
"link": "https://www.facebook.com/633917458776176/posts/671041618397093"
}
],
"icon": "https://www.facebook.com/images/icons/photo.gif",
"full_picture": "https://scontent.xx.fbcdn.net/v/t39.30808-6/362657340_671039725063949_1986257504891379817_n.jpg?stp=dst-jpg_p720x720&_nc_cat=104&ccb=1-7&_nc_sid=730e14&_nc_ohc=JUEGcDFwCbIAX8LLUaZ&_nc_ht=scontent.xx&edm=AKK4YLsEAAAA&oh=00_AfDg4f4fS8lmiw-689vpjgm1BOjvbDdzJrBoHrnpFWpCdg&oe=64C18B27",
"is_popular": false,
"is_published": true,
"shares": {
"count": 1
},
"attachments": {
"data": [
{
"url": "https://www.facebook.com/photo.php?fbid=671039728397282&set=a.554679796699943&type=3",
"description": "It's looking like tomorrow is going to be a gorgeous day for our walk at Bluff Point in Groton! This is a gorgeous walk along the water; we typically stay along the water for the best ...etc
event here: https://www.facebook.com/events/236733192428505\n\n#weadoptgreyhounds #meetandgreet #greyhoundevent #greyhounds #adoption #fosterdog",
"type": "photo",
"media_type": "photo",
"media": {
"image": {
"height": 720,
"src": "https://scontent.xx.fbcdn.net/v/t39.30808-6/362657340_671039725063949_1986257504891379817_n.jpg?stp=dst-jpg_p720x720&_nc_cat=104&ccb=1-7&_nc_sid=730e14&_nc_ohc=JUEGcDFwCbIAX8LLUaZ&_nc_ht=scontent.xx&edm=AKK4YLsEAAAA&oh=00_AfDg4f4fS8lmiw-689vpjgm1BOjvbDdzJrBoHrnpFWpCdg&oe=64C18B27",
"width": 813
}
},
"description_tags": [
{
"id": "236733192428505",
"length": 47,
"name": "July Hound Walk",
"offset": 564,
"type": "event"
}
],
"target": {
"id": "671039728397282",
"url": "https://www.facebook.com/photo.php?fbid=671039728397282&set=a.554679796699943&type=3"
},
"unshimmed_url": "https://www.facebook.com/photo.php?fbid=671039728397282&set=a.554679796699943&type=3"
}
]
},
"message_tags": [
{
"id": "236733192428505",
"name": "July Hound Walk",
"type": "event",
"offset": 564,
"length": 47
}, ... etc
],
"created_time": "2023-07-22T20:08:05+0000",
"updated_time": "2023-07-22T23:33:59+0000",
"permalink_url": "https://www.facebook.com/633917458776176/posts/671041618397093"
}
From there- we dump the data into Meilisearch, which is a whole other thing. I use my own community node for Meilisearch calls, (n8n-nodes-meilisearch), but you can just as easily use an HTTP node, and use the ‘import curl’ button to quickly build the same thing from a copy-paste out of the Meilisearch documentation.
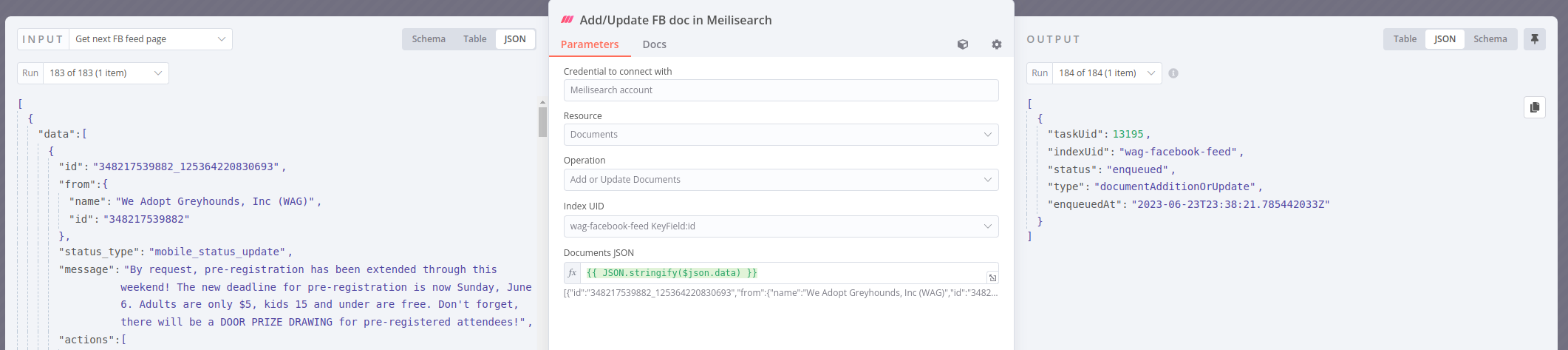
Every response may or may not have a ‘paging’ attribute. If it does, and there’s a next page, we want to get that page and dump it into Meilisearch too:
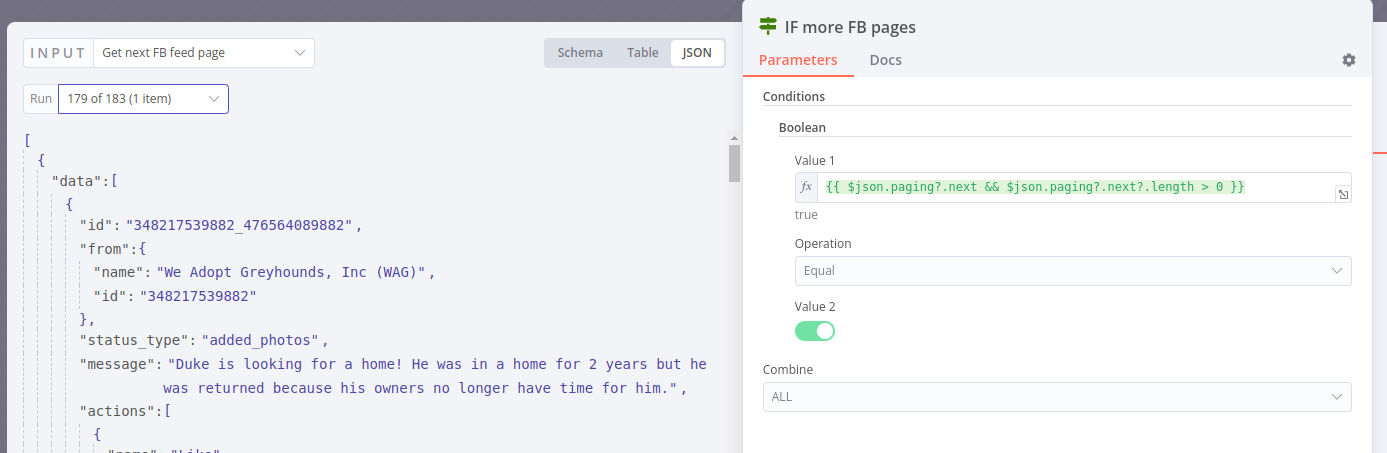
Next, if the flow proceeds from the if then there’s a next link. Let’s get that link’s data with an HTTP node:
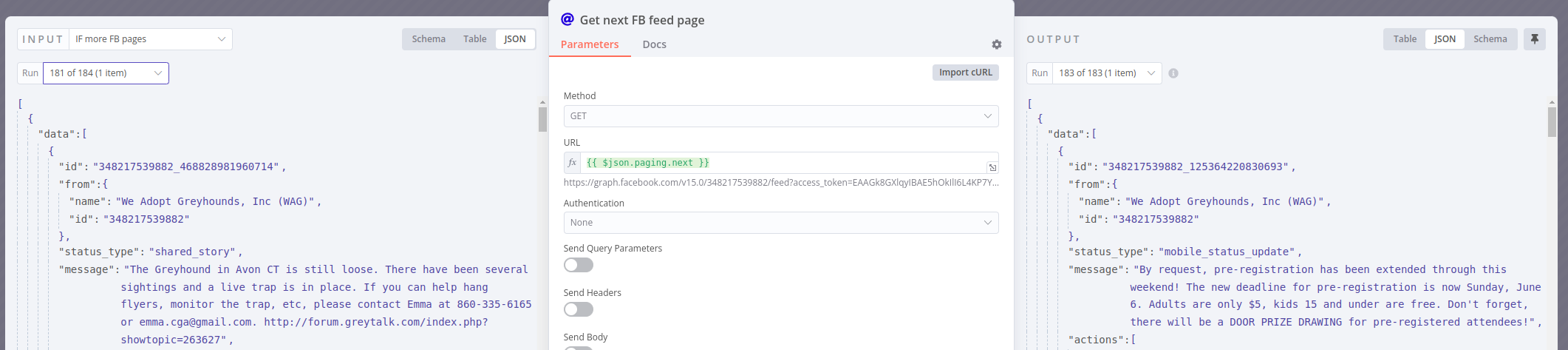
And round and round it goes! The screenshots were from an initial sync without a time limit. The actual workflow is set to run every 4 hours, and only get posts from the last day. This is to avoid getting the same posts over and over again. While that won’t hurt- (Meilisearch doesn’t care, it will see nothing changed and update nothing) I try to minimize it.
Put the images in the CDN
The way I did this may look crazy, but let’s remember there’s a lot of different media types on facebook, and I only want images and videos. Also, how do we handle Albums? How do we handle the 720px auto cropped thumbnails facebook serves?
I went through a lot of “Ohhh that’s how that works” building this flow. TLDR is- facebook image links are short lived and must be downloaded asap, if you’re not hitting the feed for every request.
So the flow is as follows:
- Query Meilisearch for all the posts that DONT have the image fields I plan to add, once the images are in the CDN
- For each post, get the attachments field, which is an array of objects
- If there’s no thumbnail field (My field, not from FB) then we need to get the image that’s cropped to 720 in the feed
- If there’s no full_picture field, then we need to get the full size image(s) from the attachments array
This is where it gets a little weird. Most media types are straight forward, but there are a few pitfalls.
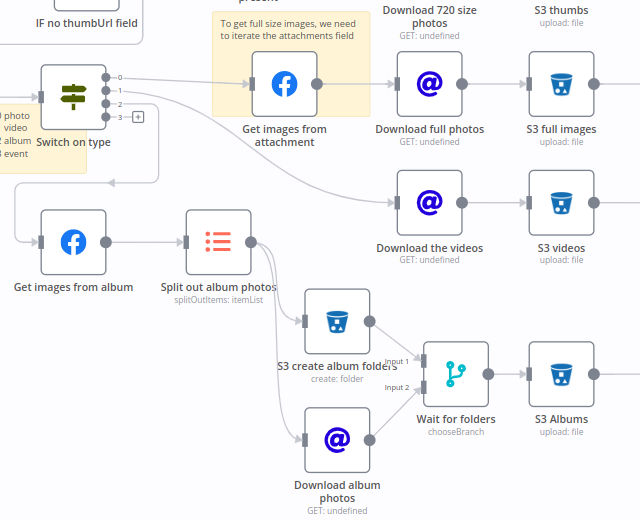
If it’s a photo- we want to get the full image, but need to use another endpoint for that. Several Facebook endpoints are … nothing. As in, the object’s ID is enough for the API to know what you want. In our case, we want to break open the Attachment ID to get all the various picture sizes, and real URLs, not php files.
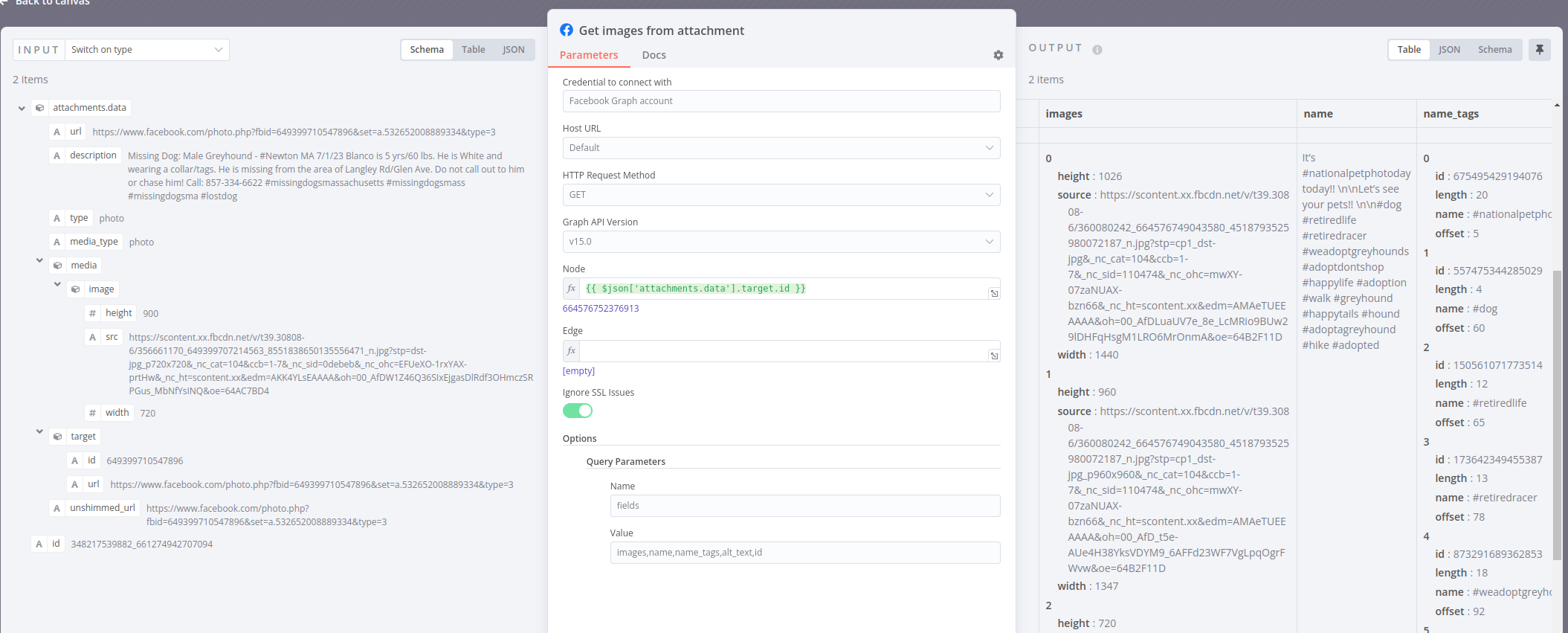
This is not perfect - if a page posts a picture that was shared, or otherwise has privacy restrictions on it such as tagging people, it will fail to fetch with a 403 because I’m not using a user token.
Once the actual image url is retrieved, we use a regular GET request to put the binary data into the workflow. From there the S3 node can upload it to the CDN:
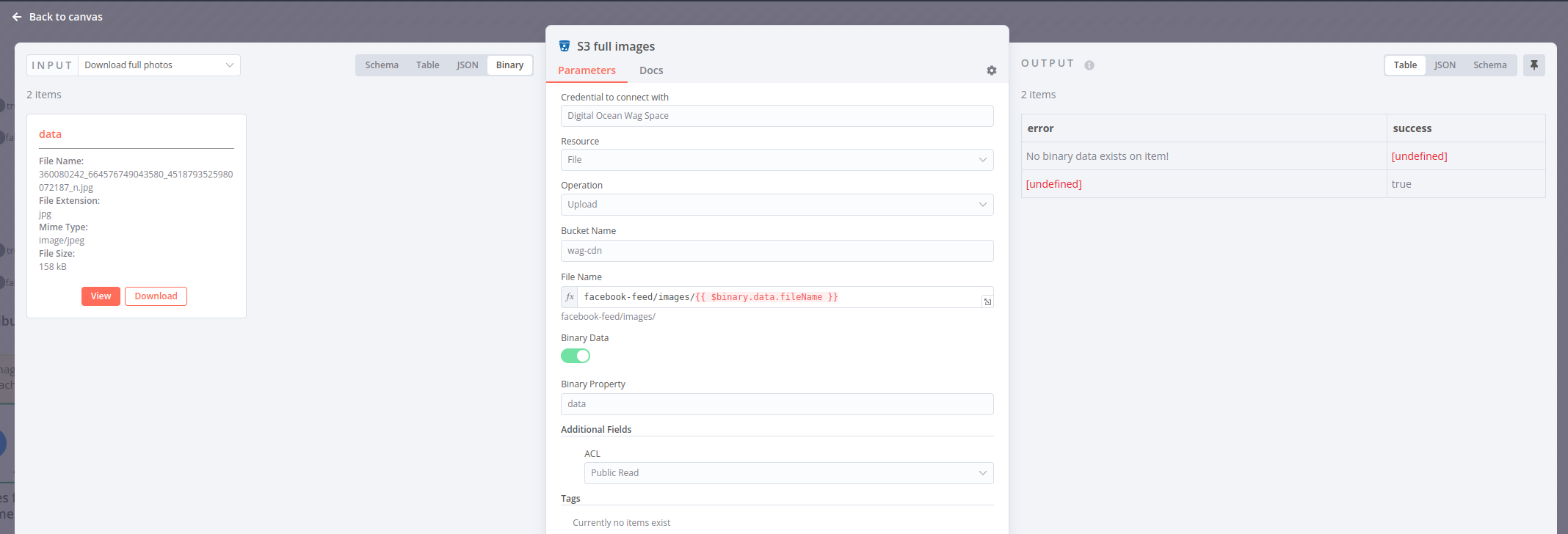
Once the image is uploaded, we update the Meilisearch document with the new image URLs, and we’re done!
Well, almost.
Meilisearch setup
Now the records are in a Meilisearch index, and they look like this:
(Expand the thingy)
Meilisearch documents
I’ve truncated or removed data for sanity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
{
"id": "348217539882_10160741394474883",
"from": {
"name": "We Adopt Greyhounds, Inc (WAG)",
"id": "348217539882"
},
"status_type": "added_photos",
"message": "Don't forget that this month, WAG is participating in the Voice program by Yummypets! ...etc",
"actions": Array with like,share,comment objects,
"icon": "https://www.facebook.com/images/icons/photo.gif",
"full_picture": "https://scontent.xx.fbcdn.net/v/t39.30808-6/287588266_10160725787754883_3240633637349824204_n.png?_nc_cat=103&ccb=1-7&_nc_sid=730e14&_nc_ohc=dujnnGH75YQAX-WQxR1&_nc_ht=scontent.xx&edm=AKK4YLsEAAAA&oh=00_AfBRWisXhSrqhjshZ5Ye5SuNt4amr-t_fnqRaNx1wUZi3w&oe=649A73CB",
"is_popular": false,
"is_published": true,
"attachments": Object,
"message_tags": [
{
"id": "225813434138918",
"name": "Yummypets",
"type": "page",
"offset": 75,
"length": 9
}
],
"created_time": "2022-06-20T13:00:06+0000",
"updated_time": "2022-06-20T13:00:06+0000",
"reactions": Object,
"likes": {
"data": [
{
"id": "348217539882",
"name": "We Adopt Greyhounds, Inc (WAG)",
"link": "https://www.facebook.com/348217539882"
}
],
"paging": {
"cursors": {
"before": "QVFIUklvd0dmb0lJbWRpbUVjU3pUU3pfRUQzeEFZAaGwyX2pkNHhBZA1BDQU5aWVlCeEdraUtqY2RhaGZA2T0RtLVZANTUZA5NU9hbF8xUnNIWnR0b3loZAndHd2JB",
"after": "QVFIUnhILUlESlV6NEFldi1SNUJHRlNBNGtzSjI2TjNfUmlzRk16bVNra1drcTlfREtyaWo2Y21QQ3lRbEpHVjRRVEpZASnVrMHNWX2xWVmZAyWS0taEhRRS1n"
}
}
},
"permalink_url": "https://www.facebook.com/348217539882/posts/10160741394474883/",
"fullImageUri": "facebook-feed/images/287588266_10160725787754883_3240633637349824204_n.png",
"fullImageUrl": "https://wag-cdn.nyc3.cdn.digitaloceanspaces.com/facebook-feed/images/287588266_10160725787754883_3240633637349824204_n.png",
"thumbUri": "facebook-feed/images/720-287588266_10160725787754883_3240633637349824204_n.png",
"thumbUrl": "https://wag-cdn.nyc3.cdn.digitaloceanspaces.com/facebook-feed/images/720-287588266_10160725787754883_3240633637349824204_n.png",
"type": "photo"
}
Meilisearch Settings
We could absolutely take some extra time in n8n to make these data objects super slim or organized, but Meilisearch makes that totally optional. What I mean by this is, for filterable, searchable, or sortable data, you can just add the fields you want to be able to filter, search, or sort on, and Meilisearch will do the rest. It’s pretty amazing.
Want to filter on a field that’s in an object, in an array? YOU CAN DO THAT. Meilisearch will flatten the object and array, and make it searchable, filterable, and sortable.
For example- filtering by the name of the tag used in the message. That’s in the array called message_tags, and in an object in that array. All we need to tell Meilisearch is that we want to add message_tags.name to the index, and it will do the rest. Yes, really.
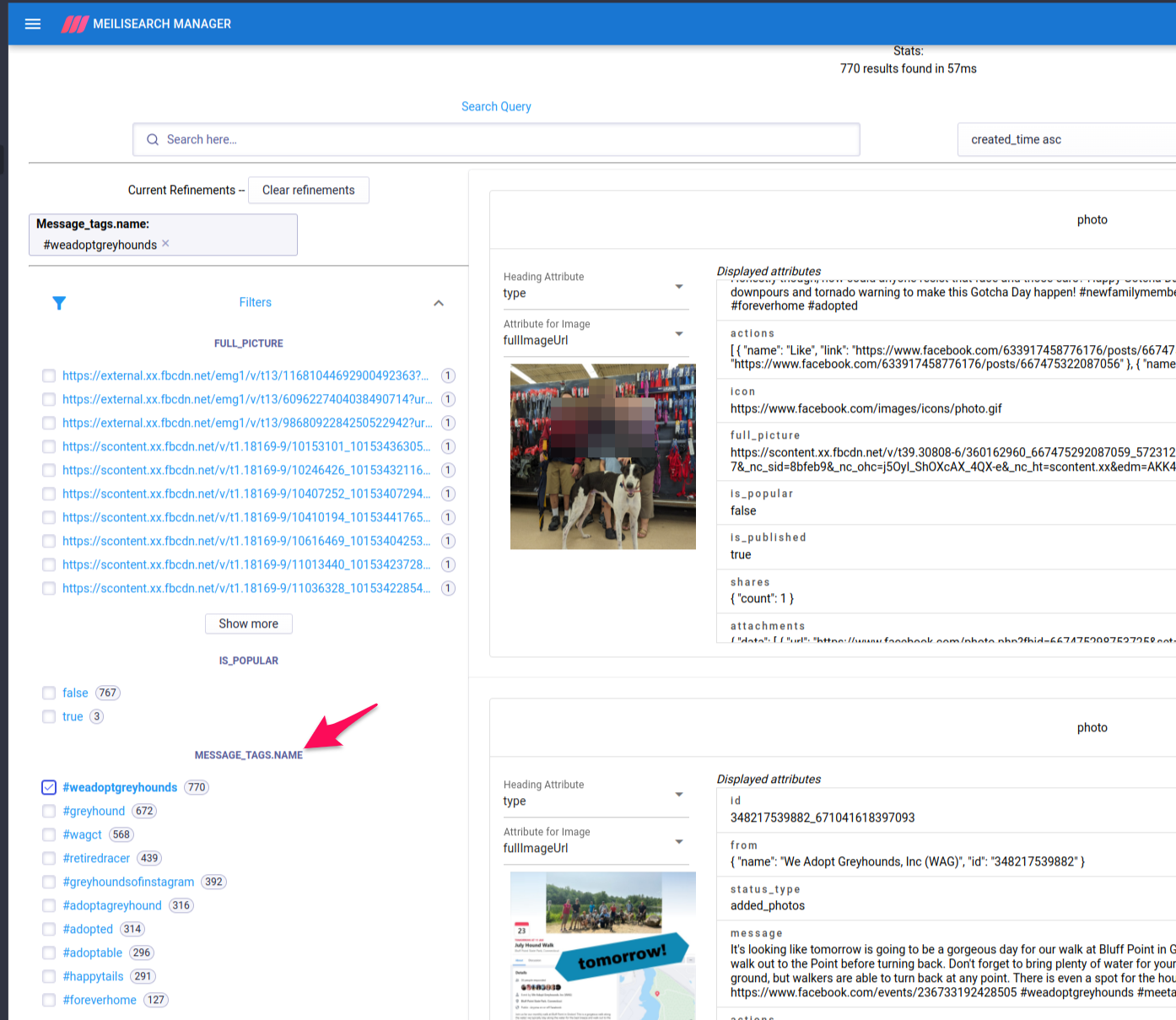
Here’s the official docs on the Meilisearch settings object. Those are important to fully understand what can be set, and what the defaults are. Part of the beauty for me is in the simplicity.
This is the entire configuration object:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
{
"displayedAttributes": ["*"],
"searchableAttributes": ["*"],
"filterableAttributes": [
"full_picture",
"is_popular",
"message_tags.name",
"status_type",
"story",
"story_tags.name",
"thumbUri",
"type"
],
"sortableAttributes": [
"created_time",
"is_popular",
"likes",
"reactions",
"shares",
"status_type",
"updated_time"
],
"rankingRules": [
"sort",
"words",
"typo",
"proximity",
"attribute",
"exactness"
],
"stopWords": [
"and",
"of",
"on",
"the",
"to"
],
"synonyms": {},
"distinctAttribute": null,
"typoTolerance": {
"enabled": true,
"minWordSizeForTypos": {
"oneTypo": 5,
"twoTypos": 9
},
"disableOnWords": [],
"disableOnAttributes": []
},
"faceting": {
"maxValuesPerFacet": 1000
},
"pagination": {
"maxTotalHits": 10000
}
}
There are other apps out there I’m sure, but I ended up making a little Vue app to manage Meilisearch instances. Feel free to use it or fork it or what not - Meili-Manager.vercel.app
Normally, you wouldn’t set “*” for Displayed Attributes. Those are the attributes returned with every api call, so the less the better.
Vue InstantSearch Setup
Ok so we have an index full of links and data. Now what?
Vue InstantSearch is a Vue.js implementation of Algolia’s InstantSearch.js library. It provides a set of components and helpers to build a search UI quickly. It’s also open-source and free to use.
This works wonderfully in combination with Instant-Meilisearch. Instant-Meilisearch is a connector that allows you to use Meilisearch as a backend for InstantSearch.js. It’s also open-source and free to use.
Vue InstantSearch Setup
1
2
3
4
5
# with npm
npm install --save vue-instantsearch
# with yarn
yarn add vue-instantsearch
Instant-Meilisearch Setup
1
npm install @meilisearch/instant-meilisearch
Implementation
With Vue-Instantsearch, we can basically copy paste from the official Algolia widget showcase documentation. Here’s the official docs for Vue-Instantsearch
In the case of WAG, we use Craft CMS, so our templates are written in twig. The markup is Tailwind, and Vue is sprinkled in where necessary or where Sprig (HTMX) just doesn’t feel right.
So to hand in data to the vue component the twig template does this:
1
2
3
4
5
6
7
8
9
10
11
12
13
...
<div class="col-span-full md:col-span-7 mt-2">
<div class="mt-3 text-base text-center text-gray-800">
<wag-facebook-feed
:context="{{ context | json_encode }}"
:body-content="{{ cardBody | json_encode }}"
:feed-query="{{ cardTitle | json_encode }}">
</wag-facebook-feed>
</div>
</div>
...
This data is received in the Vue component as props, as you may expect:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
<script setup>
...
const props = defineProps({
bodyContent: {
type: String,
required: false,
default: () => ''
},
feedQuery: {
type: String,
required: false,
default: () => ''
},
context: {
type: Object,
required: false,
default: () => ({logo: ''})
}
})
...
Then really all that’s left in relation to the search functionality is creating the initial state, and the search client:
1
2
3
4
5
6
7
8
9
10
11
const initialUiState = {
[indexName]: {
query: props.feedQuery,
}
};
//define search client
const searchClient = instantMeiliSearch(
'https://index.weeumson.com',
'READ ONLY KEY GOES HERE - THIS IS SHOWN ON THE FRONTEND'
)
Now your markup can be all sorts of crazy, but the basic components used are as follows:
Click to expand
I’ve cut out a bunch of styling but left most things intact for examples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
<ais-instant-search
:search-client="searchClient"
:index-name="indexName"
:initial-ui-state="initialUiState"
>
<div class="p-4">
<ais-search-box show-loading-indicator>
</ais-search-box>
</div>
<div class="bla bla">
<ais-stats />
<ais-sort-by
:items="[
{ value: indexName+':created_time:desc', label: 'Newest' },
{ value: indexName+':created_time:asc', label: 'Oldest'},
{ value: indexName+':updated_time:desc', label: 'Recently Updated' },
]"
class="rounded-md bg-white"
>
<template #default="{ items, currentRefinement, refine }">
...
</template>
</ais-sort-by>
</div>
<div class="bla bla">
<ais-state-results>
...
</ais-state-results>
<ais-infinite-hits>
<template #default="{ items }">
<div
v-for="post in items"
:key="post.id"
class="bla bla"
>
<div class="flex items-center justify-between mb-2">
{# Logo, Name, Date at top of card #}
<div class="flex items-center">
<img
:src="context.logo"
class="w-12 h-6 mr-2"
alt="wag logo"
>
<span class="text-sm">By: {{ post.from.name }}</span>
</div>
<div class="text-sm italic">
{{ formatTime(post.created_time) }}
</div>
</div>
{# The body of the post #}
<div>{{ post.message }}</div>
{# The image(s) of the post #}
<wag-swiper
v-if="post.album && post.album.length > 0"
:images="post.album.map(url => ({ url, attr: { data: { mimetype: 'image' } } }))"
/>
{# If not album, the image of the post #}
<img
v-else
:src="post.thumbUrl"
class="my-4 lazyload"
data-src="placeholder-image.jpg"
>
{# The footer of the post #}
<div class="flex justify-between w-full">
<div>
<a
:href="post.permalink_url"
class="wag-text-blue mr-4"
>View on Facebook</a>
</div>
<div
v-if="post.shares && post.shares.count > 0"
class="text-gray-500"
>
{{ post.shares.count }} Shares
</div>
</div>
</div>
</template>
</ais-infinite-hits>
</div>
</ais-instant-search>
I wish I had time to go into super detail about all the things here, but whatever your framework of choice- it’s remarkably easy to employ instantsearch.
The Result
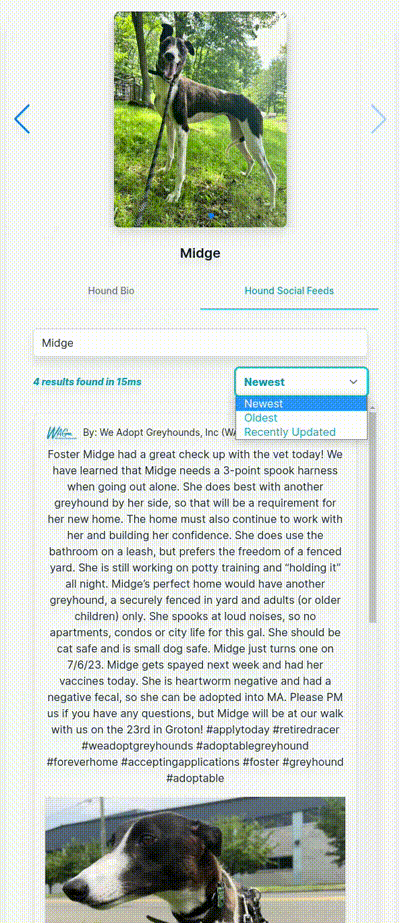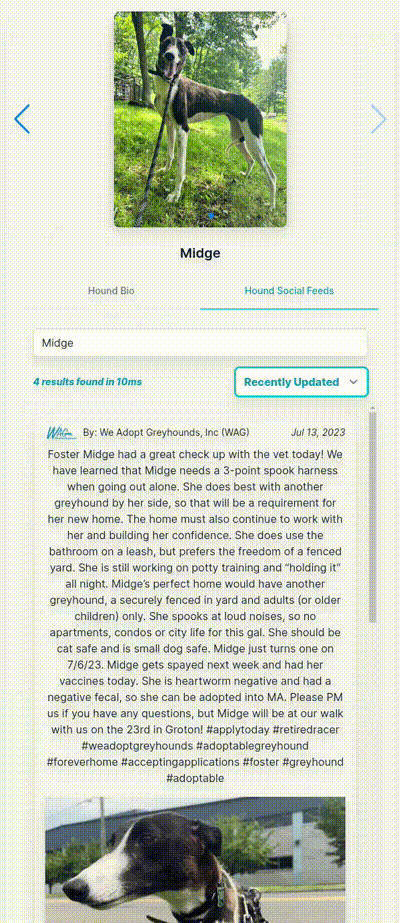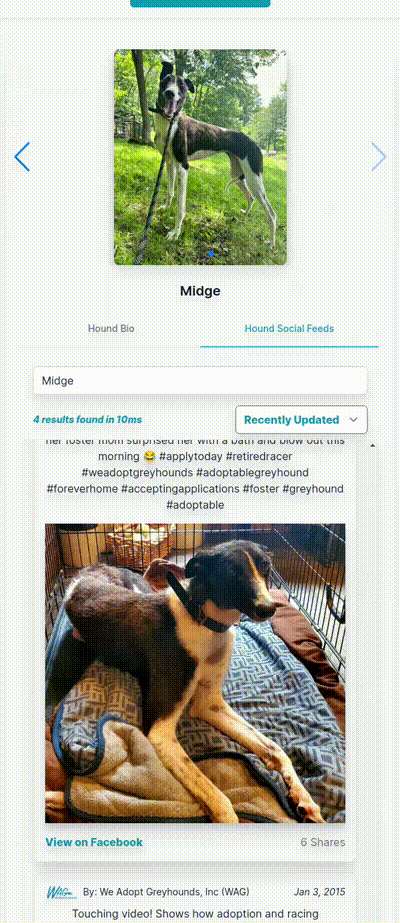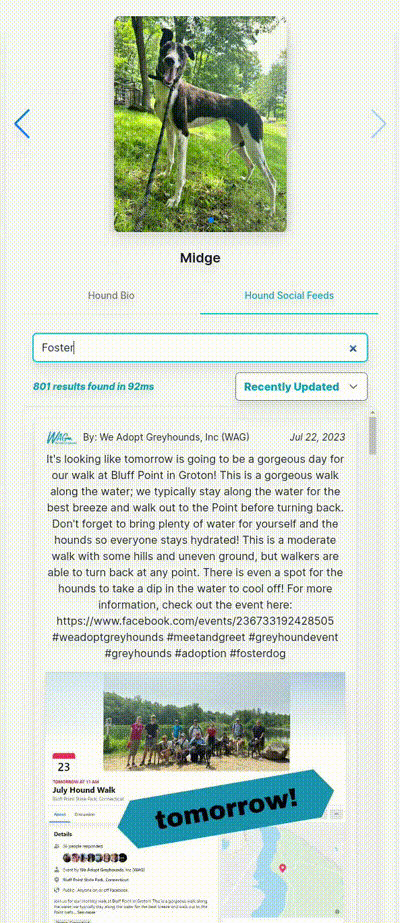
As always, I hope you found this interesting!
Comments powered by Disqus.