In short, we are pushing a csv into a database on a schedule using Talend Open Studio as our ETL tool.
For this post though, we’re getting specific with exchange tracking logs, as this was a fun task I had once so it’s a real world example. I did a short post about how I generated the csv here.
The following is a step by step overview. I suppose it could substitute for a hands-on crash course in basic Talend as well.
What the heck is Talend and ETL
Before we dive into this job, some people may be asking this question.
ETL stands for Extract, Transform, Load You may have seen or heard of some common ETL tools. Many of these tools are now services with subscriptions per row of data transferred. I used Stitch for a while and loved it. But my budget did not.
Talend Open Studio is an ETL tool. It’s also Free
You can learn more about this awesome tool here. Bookmark their forums (You’ll need them) here. Bookmark their docs here.
Talend can transfer data while transforming it from one data source to another. It’s as flexible as your imagination - so you could combine data from multiple sources, and transfer the computed and transformed data to multiple destinations.
Things I use(d) Talend for:
- Parse data files and upsert databases with the data
- Syncornize databases / data sources
- Replicate data sources for reporting and/or data warehousing
- Consuming APIs to update databases
BI, Reporting, Data Warehousing
For many of us, these are all in the same bucket. Small to medium businesses simply want their reports to work. They have tons of data sources, but no great way to digest it all.
One solution I really love is Talend and Metabase. Both free and powerful. Set up your Metabase dedicated linux server, and put some databases on it. It’s a really pretty solution for BI, Reporting, and Warehousing. Well, Metabase isn’t really for warehousing, but they do hold hands.
The Metabase Server
For this story we do have a Metabase server as our destination. This is out of scope for this story though. Check it out - it’s neato.
Story Time
We begin with Talend already installed, working and configured.
We have this CSV with Exchange Tracking Log data in it, just the columns we want. We want to dump this data into a Mysql DB under Metabase to do some reports on.
If I remember correctly, this data was overkill with the future in mind- all I really needed was email counts per user in and out. But hey, I love data so I grabbed what I thought might be handy. Also- the retention of the Mysql DB is going to be a LOT longer than that of the exchange logs.
So let’s dive in and see how this Talend job was built.
Create the job in Talend
Create a new job in your desired location. For myself, I group jobs by either system or database type, with sub-types for complex jobs that may have multiple versions. 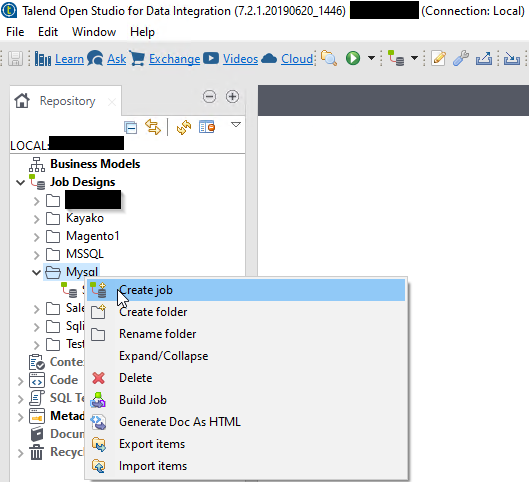
Fill in the fields you wish to. Keep in mind the version field for later- if you increment that on a big change you can roll back if needed to an earlier version. 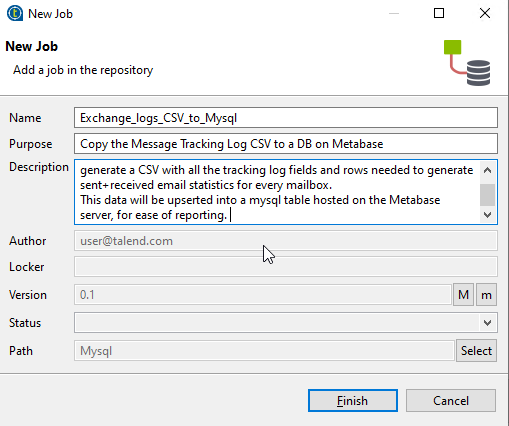
Set the stage
Once we have our job in front of us, we go and find the components we will need. In this case, we will need tFileInputDelimited to start, so drag that onto the stage. 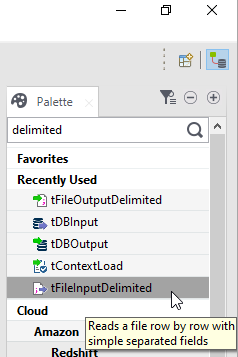
Here’s what your stage may look like. I’ve also dragged a tDBOutput component onto the stage, getting ahead of myself. 
Let’s set up the CSV component-
- Click the three dots beside the
File name/Streamfield, and go find your file. You can also type in a UNC path. - Verify skip empty rows is checked, we don’t want them here.
- If we wanted to re-use a schema, we could select it now, but in our case we’re building this plane while we fly it, so we’ll build that momentarily.
Can you spot the mistake I made here? We’ll come back to it. 
Click over to the view tab in the component tab. This is where we change the labels and hover-text. Give it appropriate data, future you will thank you. 
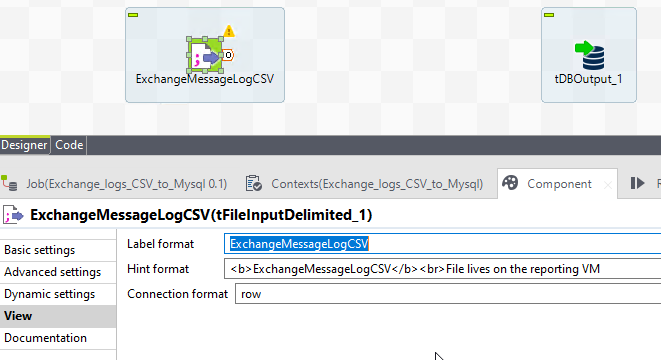
Test setup
Now, before we start throwing data willy-nilly at a database, let’s test some things. The common way to do this with almost any component, is to use a tLogRow component as your destination/output.
Drag a tLogRow component onto the stage, in between the CSV and DB components. Then, Right click on the CSV component, and grab its main output row - then click the tLogRow to connect them. ProTip: Right click-dragging from a component defaults to grabbing the row-main output. 
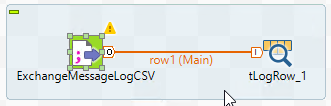
Now our tLogRow will catch all of the output from the CSV input.
Create a CSV schema
Before we can gobble up the CSV, we need to tell the component what to expect in the thing. Better practice is to always make a schema, don’t just build it in the component on the fly.
To do that, use the left nav to find the Metadata area. Under File delimited- Create folders as you like/if you wish, and create a new file delimited schema via right click->create. 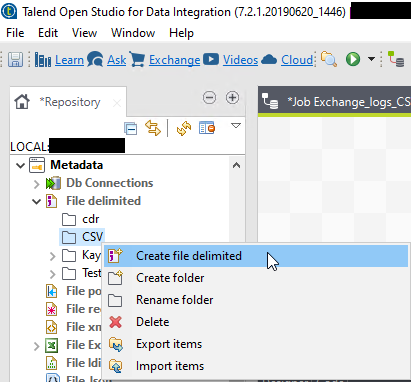
Name the schema, and all that jazz. 
Grab the CSV, and don’t worry about the preview of the data yet. 
Configure all of your delimiters, and separators. The shot below should work for the exchange logs - but if you’re using the story as a guide for some other CSV, change this as necessary. 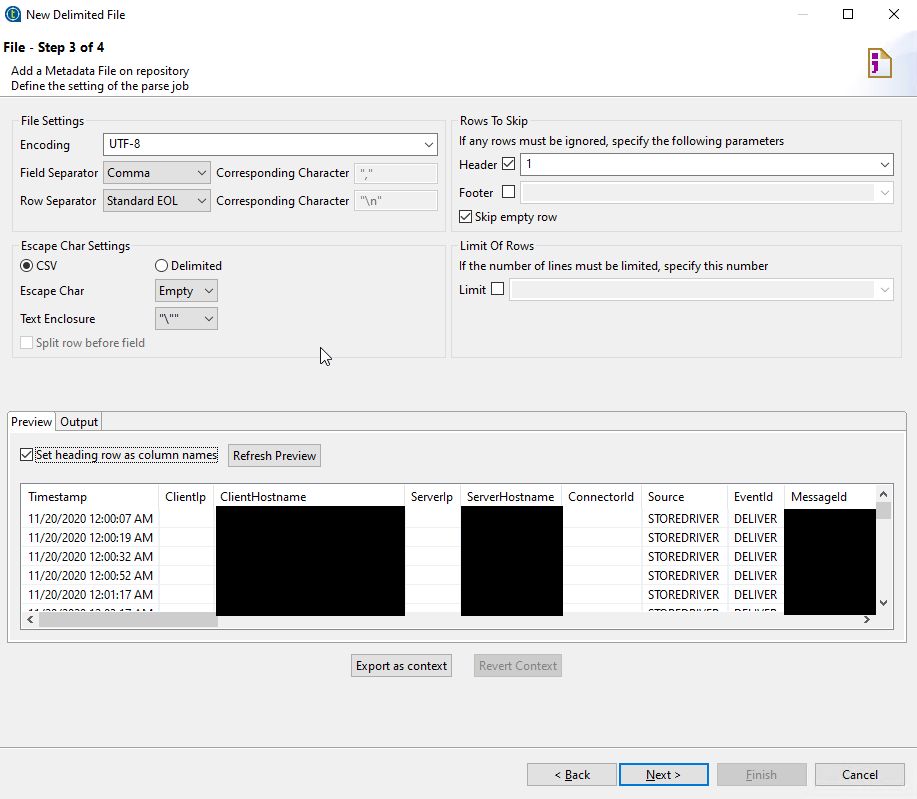
Next step- Guess the schema. It gets pretty darn close to what you want straight away. You may need/want to tweak some of this though- for instance, the length column for each field and type. I recommend increasing the Length allowance where you think it may be an issue. Also take a look at the type column- the type isn’t just for looks - the data will be expected to follow the type set for it. We will modify this as we go along as well- it’s not set in stone. 
If you change the schema, then click finish- you will be warned about the preview. That’s ok. 
There’s our schema- we can use this in any job, duplicate it and edit it etc. 
Assign the Schema
Back in the CSV component - change the schema from Built-In to Repository, and select the one you just built. 
You will see this pop up a lot. Any time you change the definition of the data, it will ask if you want to propagate changes. This can be dangerous- as sometimes propagation includes other jobs that use the same schema. So be careful- but normally, this is a very handy feature. Essentially it will push the schema definition to all the components affected by it. (We’ll say yes) 
Almost time for fun stuff- Click on the tLogRow component, and go edit it’s schema in it’s component tab. 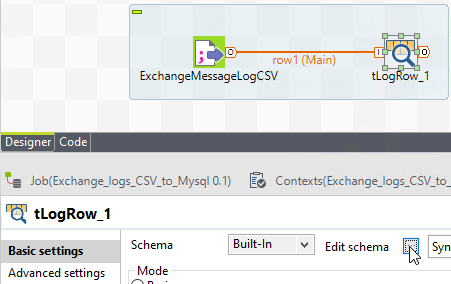
Here we can see what propagation did for us- everything is identical. Nice.
Run/Test the job
Click ok, and then click the Run tab near the component tab and click Run. It will build and execute. 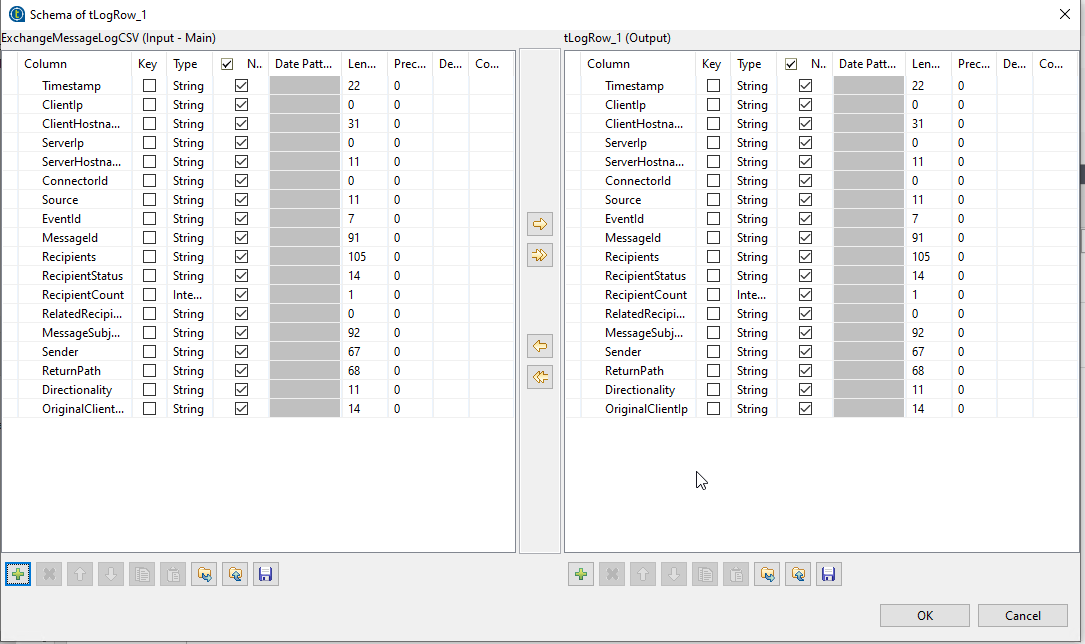
The mistake I made earlier? Yea, if you missed it too you’ll see this: Couldn't parse value for column 'RecipientCount' in 'row1', value is '"1"'. Details: java.lang.NumberFormatException: For input string: ""1"" I forgot to enable CSV options- and talend automatically wrapped most of my values in double quotes, essentially double-double quoting everything. Back to the component tab for the CSV- check off that CSV options box, and run the job again. 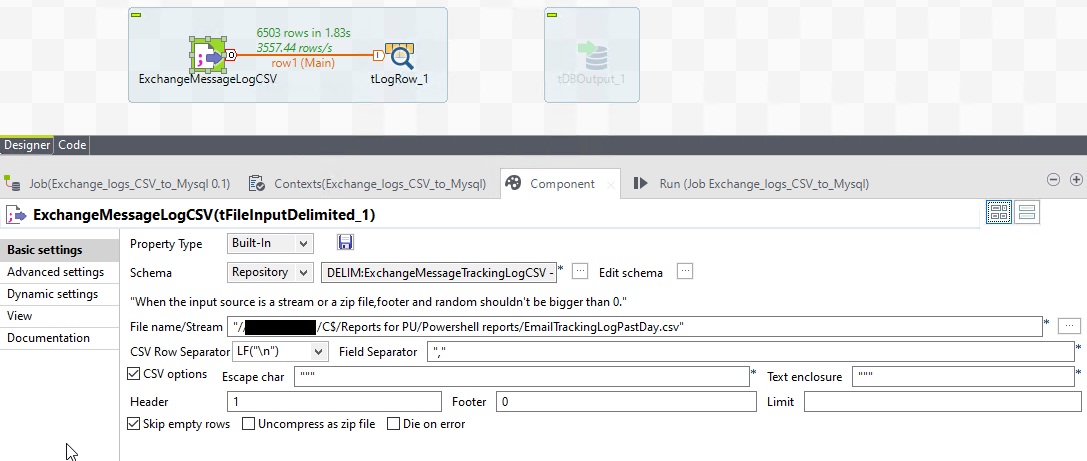
Inspect output via the Run tab, that is created by the tLogRow component. I don’t seem to have screenshots here for the config of the tLogRow - but they’re fairly straight forward. Tell it to output in a simple table like this, and run the job again if necessary. 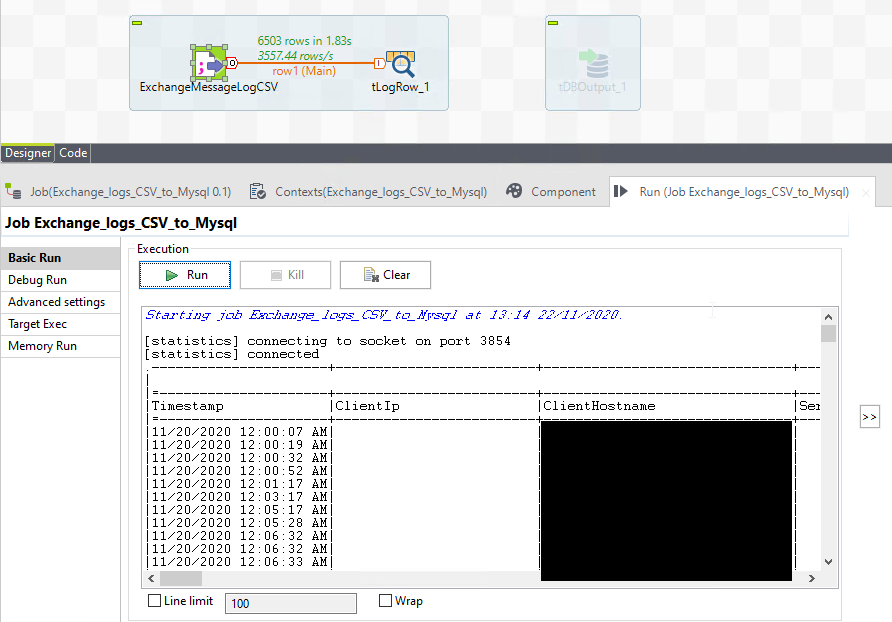
Configure and connect the DB component
Ok so the data looks sane from the log, so let’s set up the DB component. Select MySql if you’re following along, and click Apply. This will then show relevant options for it’s configuration. 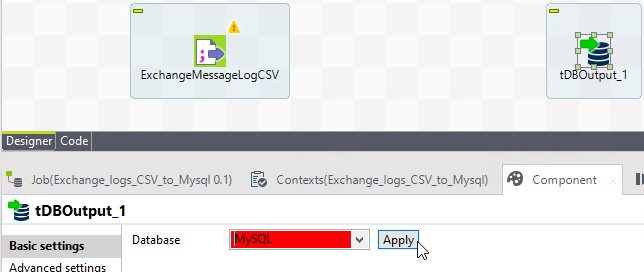
DB name here is the name of the DB you created. I find the utf8mb4 and unicode_ci to be the safest character set/collation, generally. 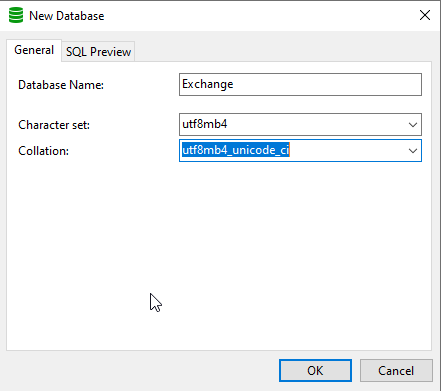
Time to create another schema! Well, sort of. We’re created connection details. Under your Db Connections in your Metadata. Fill in all the thingies on the first step. 
Second step is way cooler. The default connection string will work most of the time. But sometimes it gives us a headache due to times and timezone. After you put in your login information, add some additional parameters for safety: noDatetimeStringSync=true&serverTimezone=<YOUR TIMEZONE> Test and Finish. 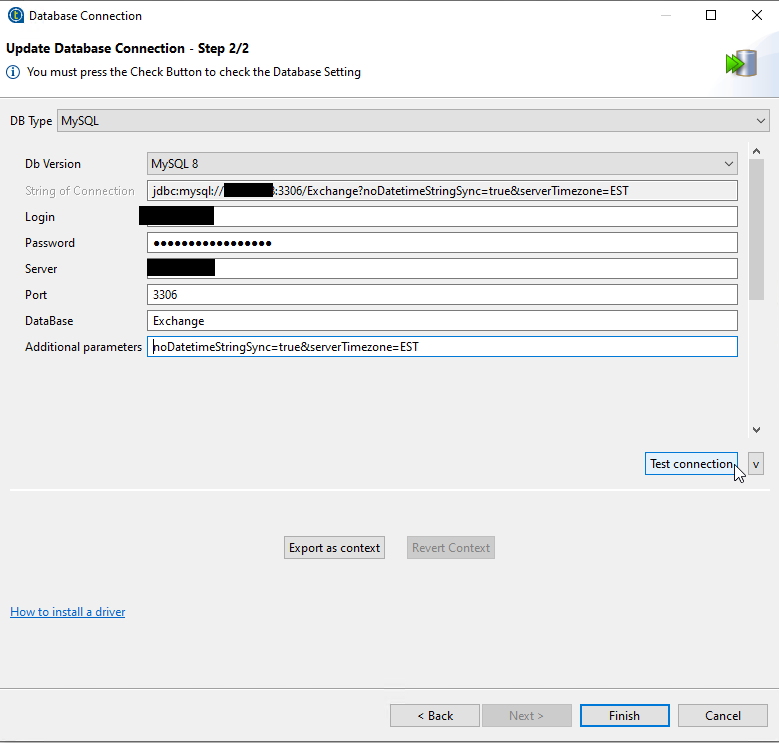
Yay 
Back over to the DB component - grab the new connection details via the ‘Property Type’ -> Repository -> … 
DB component table actions
After that is pulled in- take a close look at the options we have here under ‘Action on table’ and ‘Action on data’. Because we want to only keep unique rows, let’s use Insert Ignore. This lets us be a bit loose and fast with the data-sync, allowing overlapping data because it will simply be discarded if a conflict occurs. 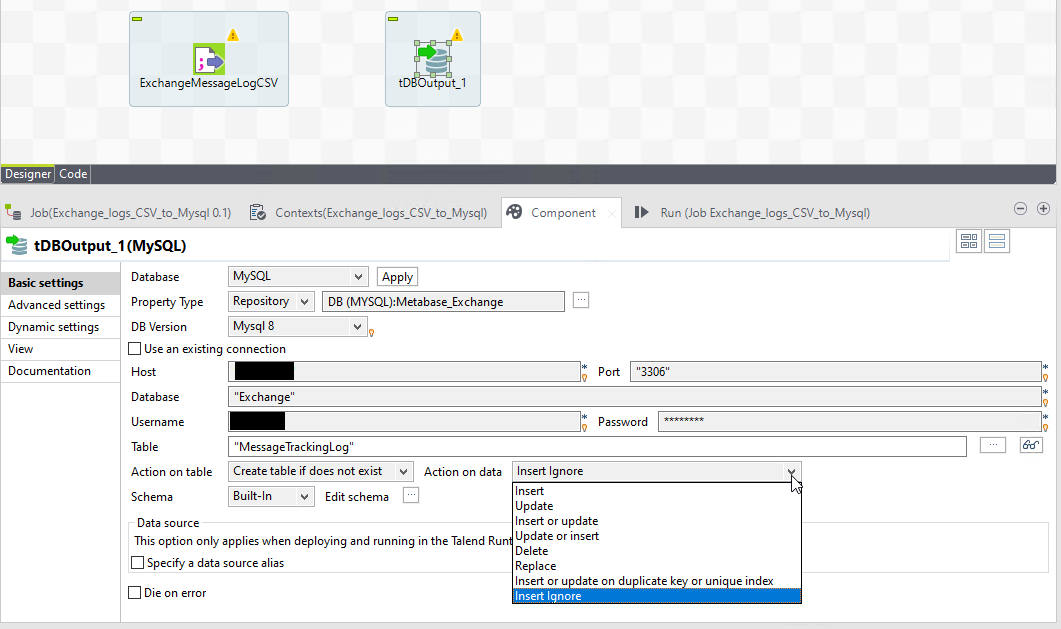
Grab your main row again from the csv, and attach it to your DB component. Then, you can ‘sync columns’ to generate a schema on the DB component. 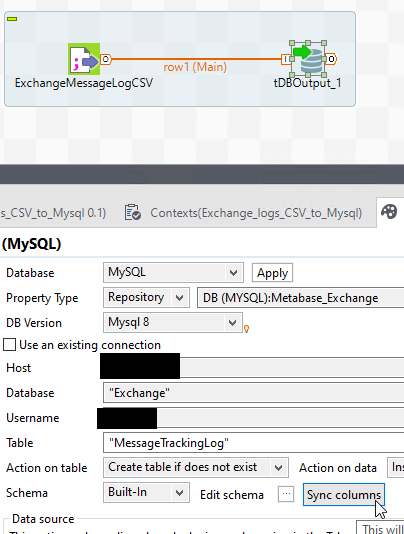
Sadly, this is not good enough. Trial and error would have told you the data is not clean enough to simply throw at the DB from the CSV.
The magical tMap component
So, a component you would be painfully familiar with after a while in Talend will come in next: The tMap. It’s magical. 
Connect your CSV to the ‘tMap’ and then try to grab the main row from it. It will ask for a name - this is arbitrary. 
Then, here’s why we did it in this order- now we can grab the schema from both sides. 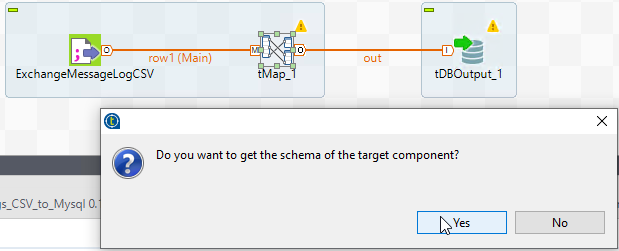
Double click your tMap component, and behold your savior and/or nightmare depending on the situation. This component really is a blessing- as long as you’re familiar with Java, you can make miracles happen here. 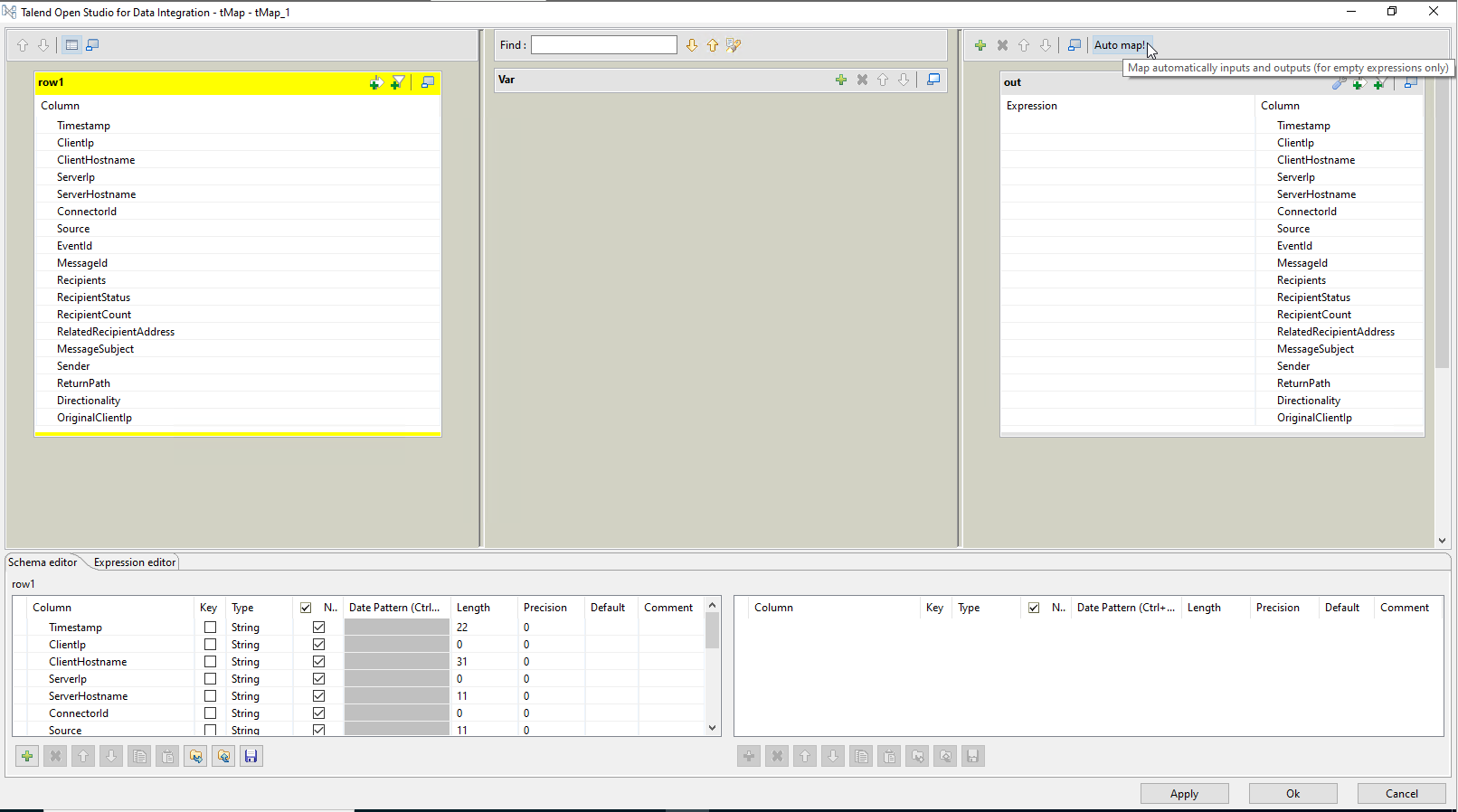
Mapping and transforming in the tMap
So the first step usually is to slam the ‘Auto map!’ button on the right. In our case it should match up everything nicely 1:1. 
Now our first problem- the Timestamp from our CSV is not OK and needs some tweaking. Change the ‘out’ side of the schema to Date type- with the pattern “yyyy-MM-dd HH:mm:ss”. This doesn’t convert the thing for us from a string, we need java for that, but if the source data was a proper ‘date’ (8601 or similar) then it would. 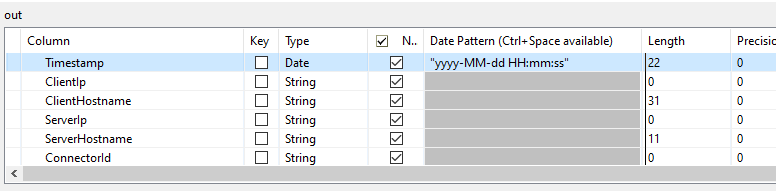
So to hand it proper data, let’s inject an expression in it- On the ‘out’ side, click the … beside the row1.Timestamp 
Neat little ISE here huh? TalendDate.parseDate("MM/dd/yyy HH:mm",row1.Timestamp) as our expression- will interpret the CSV date, as a java date proper. The schema on the out side will then store it in the format we told it to. 
Test the map
Run the tMap into the tLogRow to check that our expression worked: 
Doublecheck the DB type on the DB component is DATETIME for the Timestamp column, and re-connect the tMap to the DB component. 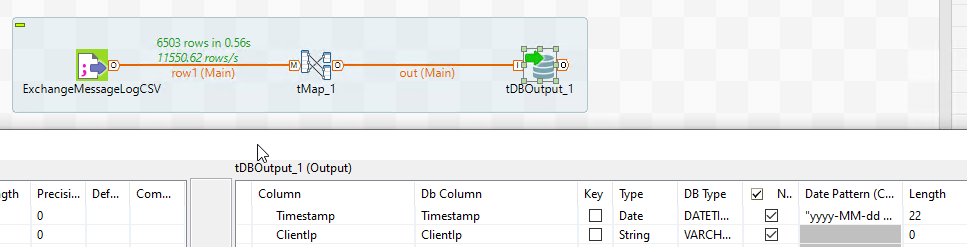
A note about unique rows with the Exchange tracking log
Now a bit of an asside-
After populating the DB with the tracking data- I saw some messages show up more than once even though we’ve narrowed the events. This is not helpful for index purposes, so because we already have the job set to insert ignore- we can truncate the table- make our unique indexes, then re-populate the table.
For the sake of statistics, I think it’s fair to exclude true duplicates. Many duplicates I found were mailboxhealth emails, and many others seemed strange even when looking at the full data- e.g. 4 ‘deliver’ events for a single message id from a single sender to a single recipient all with the exact same data including subject. I’m not sure if that was my csv import acting strangely or not. In any case we can create a unique index to weed all of these out, and rely on ‘insert ignore’ to skip the duplicates. After doing this, and reviewing the data- it’s acceptable but still not perfect. This will be a work in progress to find the best unique index without generating some sort of true PK.
Indexes on the DB to prevent duplicates
Indexes I made are simple, one for unique rows, and one for better lookups:  Repeat the above on your database as well, if you want to eliminate duplicate rows as I did.
Repeat the above on your database as well, if you want to eliminate duplicate rows as I did.
Test! Success! I hope! Talend is wicked fast eh? 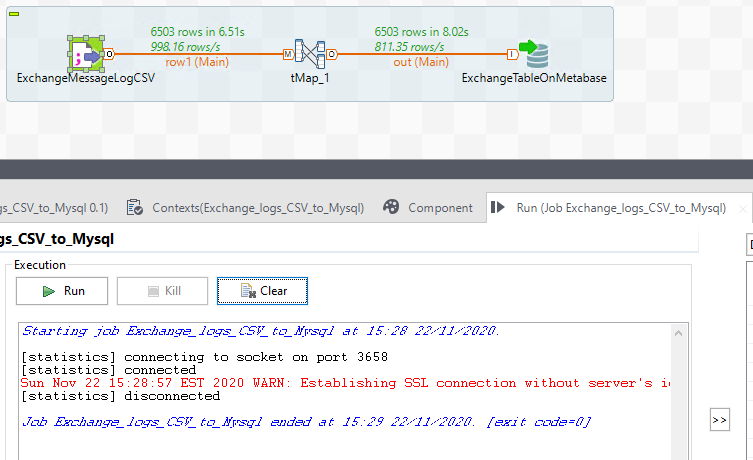
Now to build and schedule the job.
Build the job
For the uninitiated - Talend is just a workshop. You don’t need it running all the time, or even on the machine that will be running these tasks. We can compile these jobs into executables that stand alone - sweet!
So in the left nav, find your job, right click, Build Job. 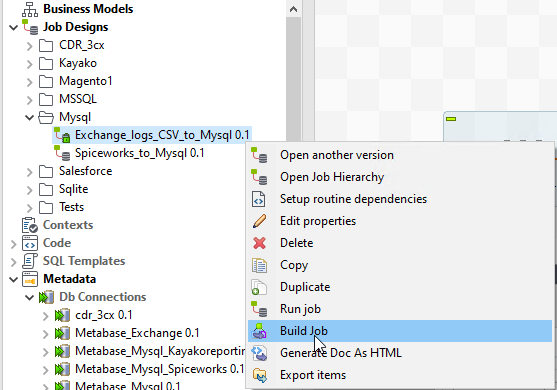
Save the job to where you want, and tell it to create All shell launchers, items, and sources. This will produce a OS fluid package of files, in which Java launches a little VM, does its job, and shuts down. 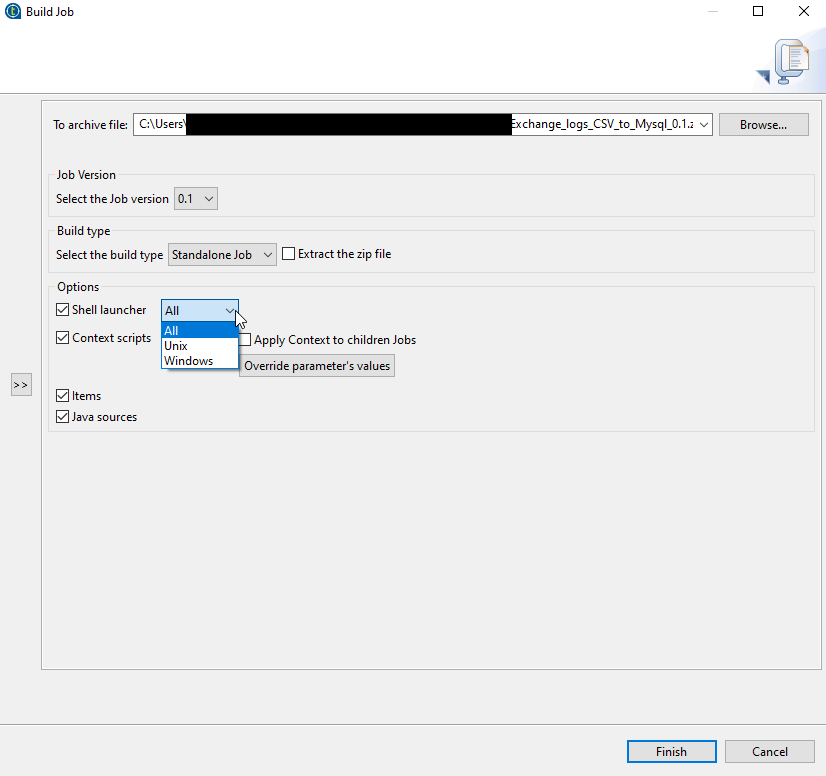
Here’s the output. If you get into more complex jobs that require context, or environment variables, you may store some config files here in the root too. 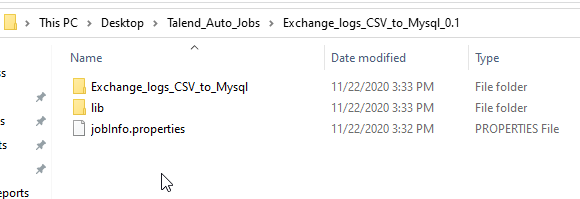
Clicking into the job folder, you’ll see the launchers- java (jar), windows bat, powershell, and bash (sh). 
In our case we’re on a windows VM - so we’ll automate this via the task scheduler, and the .bat file.
Automate the job
Create a task in task scheduler, and set it up similar to the following. Your user does not need to be the user in the database config. 
In my case, I wanted this task to run once a day, just a bit after midnight. Because in my case, I wanted to grab the previous day worth of tracking logs, and append the DB. 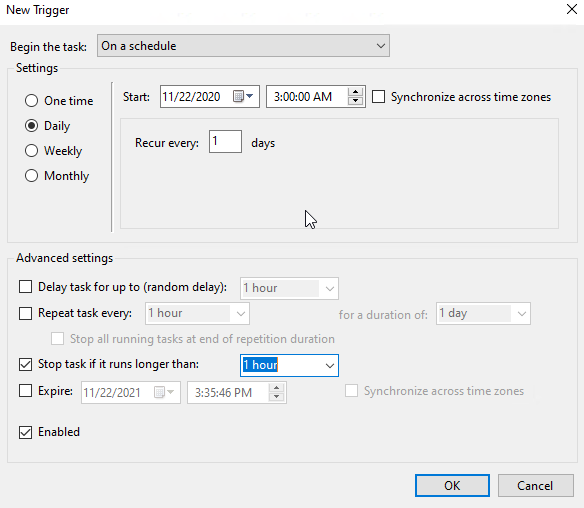
Because we’re using the .bat file- no special arguments are needed. Sweet! 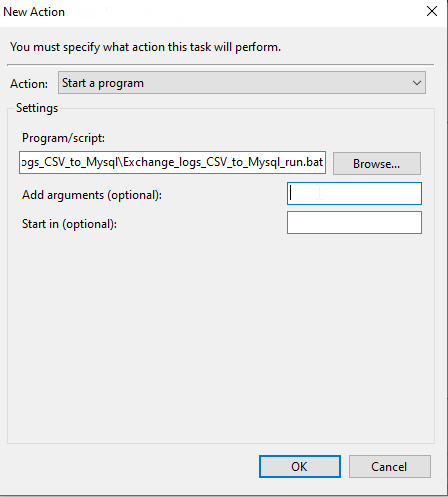
Conclusion
So this was a pretty simple example of a Talend Job, but what we accomplished was pretty cool!
- A powershell script to automatically pull exchange logs (Different post)
- A Talend job to take the output, transform it, and insert it into a Database
- All automatically, on a regular schedule.
If you have any BI tools on top of, or integrated with, the DB in question here- you now have a dataset for reporting basic email data from your exchange server.
Comments powered by Disqus.